Loop Unrolling |
| It is a programming technique that may reduce execution time for loops (for or while) in some processors. Note that most compilers perform loop unrolling, and manually incorporating "loop unrolling" is rarely beneficial. Es una técnica de programación que puede disminuir el tiempo de ejecución de los ciclos (for o while) en algunos procesadores. Note que la mayoría de los compiladores realizan "loop unrolling", y manualmente incorporando "loop unrollling" es rara vez beneficial. |
Processor Pipelining |
When a program is executed, the CPU executes the instructions in the program. Each instruction needs to go through several stages. Some common stages are (these stages depend on the processor):
Cuando un programa se ejecuta, el CPU ejecuta las instrucciones en el programa. Cada instrucción necesita pasar por varias etapas. Algunas etapas comunes son (estas etapas dependen del procesador):
|
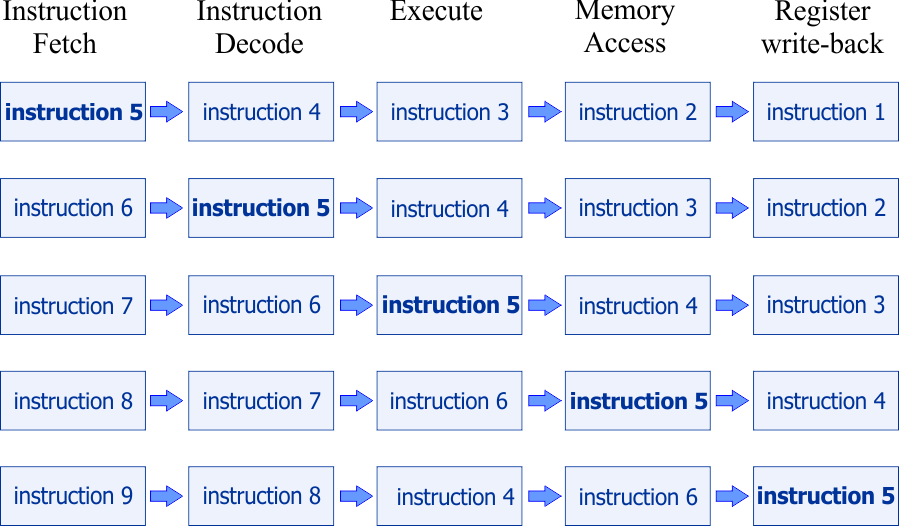
Loop unrolling and pipelining |
| When a loop is executed in a program, it is not possible to know in advance what the next instruction will be. In these specific cases, the pipeline system will not be able to efficiently operate. Loop unrolling consists of increasing the number of instructions executed in a loop as it will be shown in the following problem. Cuando un ciclo se ejecuta, no es posible conocer antes de tiempo cual será la próxima instrucción. En estos casos específicos, el sistema de pipeline no podrá operar en forma eficiente. Loop unrolling consiste en incrementar el número de instrucciones ejecutadas en un ciclo como se mostrará en el siguiente problema. |
| Problem 1 |
| Create a Wintempla Dialog application called VectorDot to compute the dot product between two vectors using "loop unrolling". Insert a textbox called tbxOutput with the multiline property. Cree una aplicación de Dialogo usando Wintempla llamada VectorDot para calcular el producto punto entre dos vectores usando "loop unrolling". Inserte una caja de texto llamada tbxOutput con la propiedad de multi-línea. |
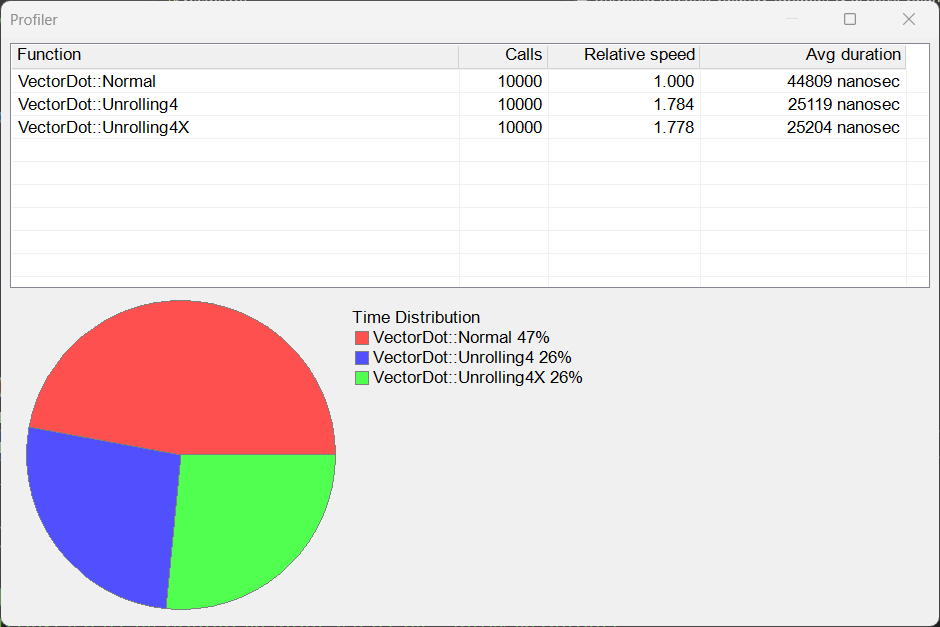
| VectorDot.h |
| #pragma once //______________________________________ VectorDot.h #include "Resource.h" class VectorDot: public Win::Dialog { public: VectorDot() { } ~VectorDot() { } double Normal(const valarray<double>& a, const valarray<double>& b); double Unrolling4(const valarray<double>& a, const valarray<double>& b); double Unrolling4X(const valarray<double>& a, const valarray<double>& b); protected: . . . }; |
| VectorDot.cpp |
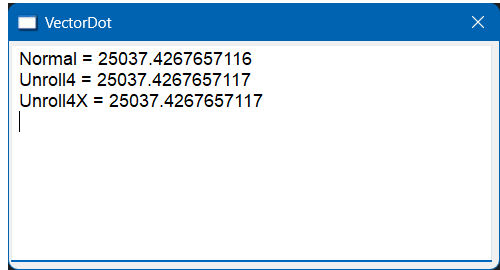
| . . . void VectorDot::Window_Open(Win::Event& e) { int i; const int vector_len = 99999; valarray<double> a, b; a.resize(vector_len); b.resize(vector_len); //_____________________________ 1. Create two vectors with random values for (i = 0; i < vector_len; i++) { a[i] = rand()/(double)RAND_MAX; b[i] = rand()/(double)RAND_MAX; } //_____________________________ 2. Compute the dot product 10000 times using Normal algorithm double average_result = 0.0; for (i = 0; i < 10000; i++) { average_result += Normal(a, b); } //____________________________ 3. Report results for the Normal algorithm wchar_t text[64]; _snwprintf_s(text, 64, _TRUNCATE, L"Normal = %.10f \r\n", average_result/10000); tbxOutput.Text += text; //____________________________ 4. Compute the dot product 10000 times using Unrolling average_result = 0.0; for (i = 0; i < 10000; i++) { average_result += Unrolling4(a, b); } //____________________________ 5. Report results using Unrolling _snwprintf_s(text, 64, _TRUNCATE, L"Unroll4 = %.10f \r\n", average_result/10000); tbxOutput.Text += text; //____________________________ 6. Compute the dot product 10000 times using UnrollingX average_result = 0.0; for (i = 0; i < 10000; i++) { average_result += Unrolling4X(a, b); } //____________________________ 7. Report results using UnrollingX _snwprintf_s(text, 64, _TRUNCATE, L"Unroll4X = %.10f \r\n", average_result / 10000); tbxOutput.Text += text; Win::Profiler::Display(hWnd); } double VectorDot::Normal(const valarray<double>& a, const valarray<double>& b) { Win::Profiler p(__FUNCTIONW__); double sum = 0.0; for (size_t i = 0; i < a.size(); i++) { sum += (a[i]*b[i]); } return sum; } double VectorDot::Unrolling4(const valarray<double>& a, const valarray<double>& b) { Win::Profiler p(__FUNCTIONW__); const size_t len = a.size(); register double sum = 0.0; register size_t i = 0; for (register size_t n = len >> 2; n != 0; n--, i += 4) { sum += (a[i] * b[i] + a[i + 1] * b[i + 1] + a[i + 2] * b[i + 2] + a[i + 3] * b[i + 3]); } for (; i < len; i++) sum += (a[i]*b[i]); return sum; } double VectorDot::Unrolling4X(const valarray<double>& a, const valarray<double>& b) { Win::Profiler p(__FUNCTIONW__); const size_t len = a.size(); register double sum = 0.0; const double* A = std::begin(a); const double* B = std::begin(b); const double* aend = std::end(a); for (register size_t n = len >> 2; n != 0; n--, A += 4, B += 4) { sum += (*(A) * (*B)) + (*(A + 1) * (*(B + 1))) + (*(A + 2) * (*(B + 2))) + (*(A + 3) * (*(B + 3))); } for (; A != aend;) sum += (*(A++) * (*(B++))); return sum; } |